
In today’s data-driven world, organizations are collecting more data than ever before. But having large amounts of data isn’t what gives a business or research team a competitive edge — it’s the quality of that data and how well it’s prepared for analysis.
This is where data cleaning and data preprocessing come in. These critical steps ensure that the data is accurate, complete, and ready for meaningful analysis, supporting reliable decision-making and powerful insights.
Why Data Quality Matters
Data analysis is not just about gathering data and converting it into what we often refer to as “useful information.” It goes far beyond that. The real value of data analysis lies in the ability to inspect, clean, transform, and model data to discover valuable insights, inform conclusions, and support decisions that align with organizational goals.
When data quality is poor; full of errors, missing values, or inconsistencies any insights drawn from it are at risk of being misleading or outright wrong. Ensuring high-quality data through cleaning and preprocessing is the foundation of effective data analysis.
Understanding Data Preprocessing
One of the most overlooked but essential phases in data analysis is data preprocessing. Yet, this step significantly impacts the accuracy and validity of downstream analyses, especially in machine learning projects.
What is data preprocessing?
Data preprocessing involves the manipulation, filtration, or augmentation of data before analysis. It prepares raw, often messy data for machine learning models and statistical evaluations by transforming it into a clean, structured, and usable form.
Raw data frequently comes with issues such as:
- Unstructured formats
- Impossible data combinations
- Missing or inconsistent values
Through preprocessing, unstructured or noisy data is converted into meaningful, intelligible representations suitable for analysis.
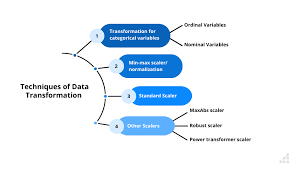
Key techniques in data preprocessing include:
- Data cleaning
- Instance selection
- Normalization
- One-hot encoding
- Data transformation
- Feature extraction
- Feature selection
These processes enhance data quality and ensure the dataset represents the problem domain accurately.
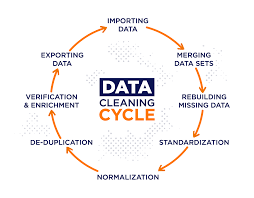
The Critical Role of Data Cleaning
Closely tied to preprocessing is data cleaning (also called data cleansing), another essential part of optimizing data quality.
What is data cleaning?
Data cleaning involves identifying and correcting or removing corrupt, inaccurate, or irrelevant records from a dataset, table, or database. It focuses on detecting incomplete, incorrect, or inconsistent parts of the data and then replacing, modifying, or deleting the affected records.
Common tools and methods used in data cleaning include:
- Data wrangling tools (e.g., Trifacta, Talend)
- Batch processing scripts (e.g., in Python, R)
- Data quality firewalls
By applying these tools and techniques, analysts can ensure that the data is trustworthy and ready for analysis.
Conclusion
The success of any data analysis or machine learning project starts with data quality. Investing time and effort in thorough data cleaning and preprocessing helps eliminate errors, reduce noise, and structure the data in a way that maximizes analytical efficiency and effectiveness.